I am sometimes asked to assist in matters which involve detection of genetically modified organisms (GMO). This is very important in some trades as many countries have lists of approved cultivars and stricly only those are permitted to be present. Organic trade is also highly sensitive to contamination by anything which is not appropriately certified as organic.
The technology to detect the presence of modified organisms, and identify any which are present, is very advanced but you need to have an understanding of what the tests are, how they work, and what they look for in order to understand what results do or do not mean. As with many things, the first step in testing is obtaining reliable samples. If the samples are not properly representative of the goods in question, the testing results will not be useful.

Anything related to genetics generally has its basis in DNA. DNA stands for deoxyribosenucleic acid and it contains the information required to make the proteins out of which life is built. The double-helix structure of DNA is like a ladder which has been twisted. The backbone structure (made up of deoxyribose sugars) forms the sides of the ladder and the rungs are nucleic acid pairs. Each chain of deoxyribose sugars has a sequence of nucleic acids, each of which is hydrogen bonded to a complementary nucleic acid on the other half of the ladder.
There are four nucleic acids, which are adenine, thymine, cytosine and guanine (denoted A, T, C and G). They are known as bases. A always pairs with T, C always pairs with G. Thus if you were to pull apart the two strands of DNA and throw one strand away, the nucleic acid sequence for the missing strand can be recreated by matching to the remaining strand. This property of DNA is what makes it possible for it to be reproduced. Thus, when DNA is duplicated in a cell, this happens by the DNA splitting into two strands, on each of which a replacement complemetary strand is created. Without this property, life as we know it would not be possible.
The genetic information in DNA consists of the bases and the order in which they are found. DNA is found in the nucleus of the cells and the information in it is used to make proteins and enzymes etc. The first stage in this process is that the DNA is transcribed to RNA. A part of the DNA is separated into two strands, and one strand is used to make an almost copy of part of the DNA sequence. RNA stands for ribose nucleic acid. This is very similar to DNA except the sugar backbone is ribose itself rather than deoxyribose. RNA consists of a sequence of bases which are complimentary to the DNA it has been transcribed from, but RNA does not use thymine; instead the RNA has uracil (U). Thus a DNA sequence made up of bases such as GATTACA would be transcribed into RNA as CTUUTGT.
The RNA transcription (referred to as messenger RNA or mRNA) is then transported out of the nucleus to a different part of the cell known as a ribosome. There the genetic information is translated into the product for which it codes. To do this, individual amino acids are added to a protein chain which gradually builds up to be the product. The bases on the mRNA are taken three at a time, and combinations of bases code for different amino acids. A group of three bases is known as a codon. The table below contains the so-called genetic code – i.e. what amino acid a given codon/combination of three bases codes for.
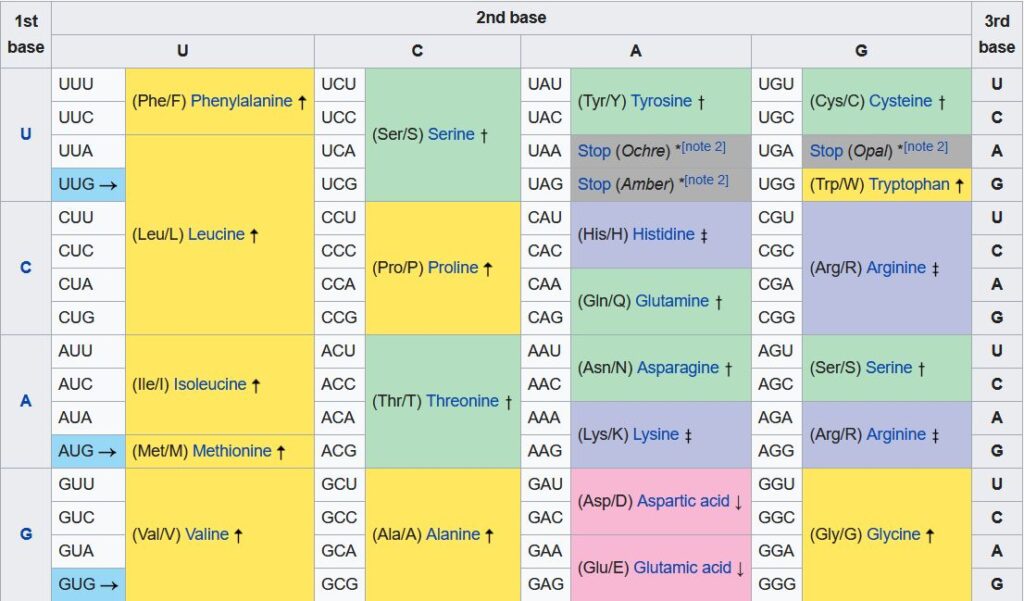
Thus a triple which reads GCC would result in alanine being added to the protein chain, and so on. The order of the bases in the codon matters, and also it is important to note that if the “reading frame” is shifted by a base pair, the product is different. Thus CUUAGUGGU codes for leucine followed by serine and then glycine, but if a base is removed from the beginning of the sequence, the resulting UUAGUG… codes for leucine followed by valine.
This then is known as the central dogma of molecular biology, stated in very simplified form as

The arrows designate information flow. All life on earth relies on this.
As an aside, there are occasions when information flows from RNA to DNA. So-called retroviruses such as HIV contain RNA. Part of that RNA codes for a special enzyme known as “reverse transcriptase”. This converts the viral RNA to DNA which is then inserted into the target cell DNA for replication by the host cell when it replicates. Sneaky! Coronaviruses such as COVID-19 are also RNA viruses but they code for enzymes which replicate the RNA to RNA, they don’t usually get inserted into the host DNA.
GMOs and gene editing techniques all rely on modifying the DNA sequences to produce a desired product. That product will tend to involve the plant (usually) cells producing proteins the native plant type cannot or does not.